¶ Storage (Longhorn, NFS & MinIO)
¶ Storage Tiers
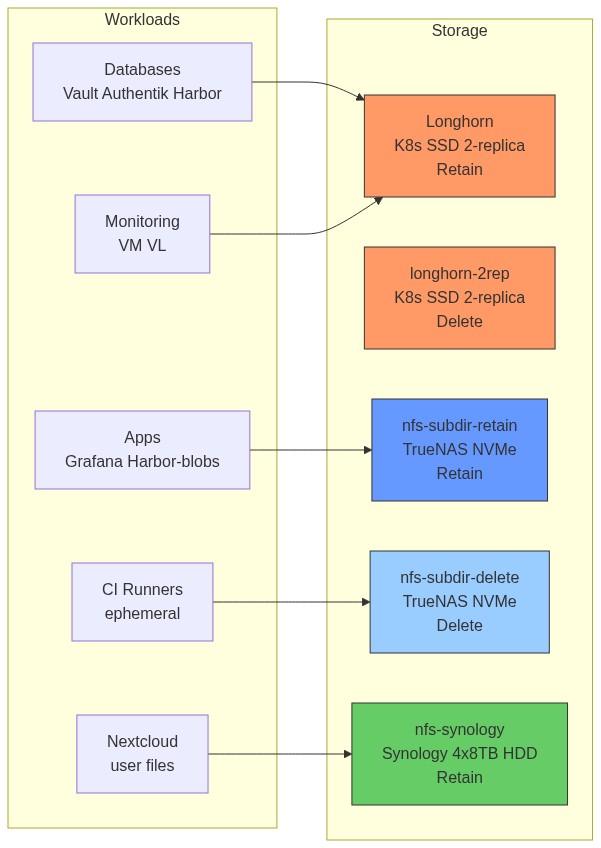
The cluster uses four storage tiers, each optimised for a different workload type. The choice of tier determines performance, availability, and capacity trade-offs.
| Class | Backend | Media | Reclaim | Best For |
|---|---|---|---|---|
longhorn |
K8s nodes (Longhorn CSI) | SSD, 2-replica | Retain | Databases, critical stateful apps |
longhorn-2rep |
K8s nodes (Longhorn CSI) | SSD, 2-replica | Delete | Same as longhorn — explicit 2-replica class |
nfs-subdir-retain |
TrueNAS 192.168.88.230 | NVMe SSD | Retain | Shared blobs, logs, metrics, RWX |
nfs-subdir-delete |
TrueNAS 192.168.88.230 | NVMe SSD | Delete | Ephemeral CI runner workspaces |
nfs-synology |
Synology 192.168.88.19 | 4×8TB HDD | Retain | Large user files, bulk capacity |
¶ How Dynamic Provisioning Works
When a Pod requests a PersistentVolumeClaim (PVC), Kubernetes orchestrates storage creation automatically:
Pod requests PVC
│
▼
StorageClass selected
(e.g. "longhorn" or "nfs-subdir-retain")
│
▼
External Provisioner (CSI driver / NFS subdir) receives claim
│
├─── Longhorn: creates replicated block volume on node disks
│
└─── NFS subdir: creates subdirectory on NFS server,
returns NFS mount path as PV
│
▼
PersistentVolume (PV) created and bound to PVC
│
▼
Pod mounts the PV via kubelet
Reclaim policy controls what happens when the PVC is deleted:
Retain— PV stays, data is safe. The PV must be manually cleaned up.Delete— PV and underlying storage are deleted automatically.
¶ Storage Architecture
Note: TrueNAS NFS PVCs are backed up via Velero (Kopia fs-backup), not directly. Longhorn PVCs are backed up by Longhorn itself to MinIO.
¶ NFS — Synology (Bulk Storage)
¶ Storage Class
| Setting | Value |
|---|---|
| StorageClass | nfs-synology |
| Reclaim Policy | Retain |
| Access Mode | ReadWriteMany |
| Chart | nfs-subdir-external-provisioner v4.0.18 |
| Namespace | nfs-storage, sync wave 3 |
| NFS Server | 192.168.88.19 (Synology DS920+, 4×8TB HDD) |
| Protocol | NFSv4 |
¶ How the NFS Subdir Provisioner Works
The nfs-subdir-external-provisioner does not manage volumes at the block level. Instead, it:
- Watches for new PVC requests that reference its StorageClass
- Creates a subdirectory on the NFS server named
<namespace>-<pvcname>-<pvname>/ - Creates a PersistentVolume that mounts that subdirectory via NFS
- Binds the PV to the PVC
All "volumes" on a single StorageClass share the same underlying NFS export — only the subdirectory path differs. This is why ReadWriteMany works: NFS allows multiple nodes to mount the same export simultaneously.
On PVC deletion with Retain policy, the subdirectory is not removed (it is renamed with an archived- prefix). The data persists and must be cleaned up manually.
¶ Root Squash Gotchas
Synology's NFS uses root_squash, which remaps root (uid 0) to uid 1024 (the Synology admin user). Any container process running as root that tries to write to this NFS mount will be remapped to uid 1024 — which may not own the directory.
Required configuration for any Helm chart using nfs-synology:
# All pods must run as the NFS owner
podSecurityContext:
runAsUser: 1024
runAsGroup: 1024
fsGroup: 1024
# Disable chown init containers — they run as root and fail
initChownData:
enabled: false
# For pods that bind port 80 (e.g. Nextcloud), root_squash also
# blocks privileged port binding — workaround:
podSecurityContext:
sysctls:
- name: net.ipv4.ip_unprivileged_port_start
value: "80"
# First deploy is slow — NFS rsync of many small files
# Use generous startup probes to avoid premature pod kills
startupProbe:
failureThreshold: 60
periodSeconds: 10
¶ Synology ACL Gotcha (Docker on NAS)
When running Docker containers on the Synology NAS itself (not via K8s), directories on BtrFS volumes have + ACLs (drwxrwxrwx+). These extended ACLs are not visible via standard POSIX chmod/chown. Inside a Docker container, these directories appear as dr-xr-xr-x (read-only), causing EACCES errors even though the host permissions look correct.
Why it happens: The Linux kernel inside Docker translates BtrFS+ACL permissions differently from DSM. The + ACL takes precedence and the container sees the ACL's effective permissions, which collapse to read-only for non-owner UIDs.
Fix: Use Docker named volumes instead of bind mounts for writable directories. Named volumes are stored in Docker's internal storage (/var/lib/docker/volumes/) on a standard Linux filesystem without Synology ACLs.
CPU limits on Synology Docker: The Synology kernel does not support the CPU CFS scheduler. Setting cpus: or cpu_shares: in docker-compose causes NanoCPUs can not be set errors. Use only memory limits (mem_limit, mem_reservation).
¶ NFS — TrueNAS (NVMe Performance)
¶ Why a Separate NFS Tier?
Synology uses spinning HDDs (4×8TB, ~200 MB/s sequential). For workloads that need faster random I/O — metrics storage, registry blobs, CI artifacts — TrueNAS Scale on an NVMe SSD provides significantly better performance.
TrueNAS (VMID 109 on Proxmox) has a 931GB ZFS pool on a single NVMe SSD. It runs NFS via TrueNAS SCALE's built-in NFS server.
¶ Storage Classes
| StorageClass | Reclaim Policy | Use Case |
|---|---|---|
nfs-subdir-retain |
Retain | Shared blobs, Grafana data, Harbor artifacts |
nfs-subdir-delete |
Delete | Ephemeral CI runner workspaces (auto-cleaned) |
The same nfs-subdir-external-provisioner chart is deployed twice with different configurations — one per StorageClass.
¶ NFS Thread Count (Critical)
TrueNAS defaults to 2 NFS server threads. Under concurrent K8s load (many pods doing I/O simultaneously), 2 threads saturate, the TrueNAS KVM process pins at 100% CPU, and NFS becomes unresponsive.
Permanent fix — set threads to 8:
curl -u "andy:<password>" -X PUT https://192.168.88.230/api/v2.0/nfs \
-H "Content-Type: application/json" \
-d '{"servers": 8}'
See Incident Reports (INC-001) for the full post-mortem.
¶ NFS Exports
| Export Path | StorageClass | Notes |
|---|---|---|
/mnt/nas/k8s-data/pvc-retain |
nfs-subdir-retain |
Persistent data |
/mnt/nas/k8s-data/pvc-delete |
nfs-subdir-delete |
Ephemeral, auto-cleaned |
¶ Longhorn (Block Storage)
¶ How Longhorn Works
Longhorn is a distributed block storage system that runs entirely inside Kubernetes. It uses the node's local disks and replicates data across multiple nodes for high availability.
Write path:
- Application pod writes to a block device via the Longhorn CSI driver
- The CSI driver sends the write to the Longhorn Engine (a per-volume controller running as a pod)
- The Engine fans out the write to 2 replicas (default;
longhorn-2repalso uses 2) - Each replica writes to its local disk
- Write is acknowledged only after all replicas confirm
Read path:
- Application reads from the block device
- Longhorn Engine reads from the local replica (same node) for lowest latency
- If the local replica is unavailable, reads from a remote replica
Failure handling:
- If one node goes down: the other replica continues serving. Longhorn marks the failed replica as faulted and rebuilds it when the node recovers.
- If both nodes hosting replicas go down: the volume becomes read-only (no quorum). This protects data integrity.
¶ Deployment
| Setting | Value |
|---|---|
| Helm Chart | longhorn v1.10.0 |
| Namespace | longhorn-system |
| Sync Wave | 3 |
| UI | https://longhorn.homelab.vyanh.uk |
| Per-node disk | 91.28 Gi (local SSD on each of 3 workers) |
| Current allocation | ~78 Gi (85%) — watch this carefully |
| Replica count | 2 (default — set via defaultReplicaCount: 2 in values) |
¶ Storage Classes
| StorageClass | Replicas | Reclaim | Notes |
|---|---|---|---|
longhorn |
2 (default) | Retain | Default class — used for all critical stateful apps |
longhorn-2rep |
2 (explicit) | Delete | Same replica count, Delete reclaim — used by Technitium PVCs |
¶ Capacity Warning
With 3 nodes at 91Gi each = ~273Gi raw, but effective capacity with 2 replicas is ~136Gi. Current allocation of ~78Gi leaves reasonable headroom, but watch when adding new stateful workloads.
To change storage class on an existing StatefulSet (volumeClaimTemplates are immutable):
# 1. Disable ArgoCD auto-sync to prevent it fighting you
kubectl patch application <name> -n argocd --type=json \
-p '[{"op":"remove","path":"/spec/syncPolicy/automated"}]'
# 2. Dump the database FIRST (if PostgreSQL)
kubectl exec -n <ns> <postgres-pod> -- pg_dump -U postgres <db> > backup.sql
# 3. Delete the StatefulSet WITHOUT deleting pods (cascade=orphan keeps pods running)
kubectl delete sts <name> -n <ns> --cascade=orphan
# 4. Delete the old PVC
kubectl delete pvc <pvc-name> -n <ns>
# 5. Kill the orphaned pod (it will be recreated by ArgoCD with new PVC)
kubectl delete pod <pod-name> -n <ns>
# 6. Re-enable ArgoCD auto-sync and force sync
# ArgoCD will recreate the StatefulSet with the new storageClassName
# 7. Restore the database
kubectl cp backup.sql <ns>/<new-pod>:/tmp/restore.sql
kubectl exec -n <ns> <new-pod> -- psql -U postgres -f /tmp/restore.sql
¶ MinIO Object Storage
¶ How MinIO Integrates With the Cluster
MinIO exposes an S3-compatible REST API. Services in the cluster use it differently:
| Service | How MinIO is Used |
|---|---|
| Longhorn | Block-level backup: uploads 2MB content-addressed chunks |
| Velero | Backup manifests (JSON) + Kopia data chunks |
| Harbor | Image layer storage: each OCI layer stored as an S3 object |
| Tempo | Trace span storage: each trace stored as a Parquet/JSON object |
| pg_dump | Single-file upload per database per day |
Why MinIO instead of Synology S3? Synology's S3 API implementation has known compatibility issues with some clients (particularly Longhorn). MinIO running in a Docker container on the NAS provides a fully compatible, well-tested S3 server.
¶ Buckets and Users
| Bucket | User | Policy | Consumer |
|---|---|---|---|
longhorn-backups |
longhorn |
longhorn-policy |
Longhorn daily volume backups |
velero-backups |
velero |
velero-policy |
Velero K8s + NFS PVC backups |
tempo-traces |
tempo |
tempo-policy |
Tempo distributed trace storage |
harbor-registry |
harbor-registry |
harbor-registry-policy |
Harbor container image blobs |
db-backups |
db-backup |
db-backup-policy |
pg_dump CronJobs (all 4 namespaces) |
Each user has a least-privilege IAM-style policy: s3:* on their bucket only, s3:GetBucketLocation (required by AWS SDK for client initialisation). No cross-bucket access.
¶ Harbor + MinIO: disableredirect: true
When Harbor stores images in S3, clients normally get a presigned URL redirect — the client is redirected to MinIO to download the layer directly. MinIO supports presigned URLs, but the redirect host (192.168.88.19) may not be reachable from outside the cluster.
Setting disableredirect: true in Harbor's S3 config disables the redirect. Harbor fetches the data from MinIO itself and proxies it to the client. This is slightly slower but works from any network.
¶ Accessing MinIO CLI
# MinIO CLI (mc) is inside the container — no local install
alias mc='ssh 192.168.88.19 PATH=/usr/local/bin:/usr/bin:/bin docker exec minio mc'
# List all buckets and their sizes
mc du local/
# List contents of a bucket
mc ls local/velero-backups/backups/
# Copy a file out (to NAS /tmp, then scp it down)
mc cp local/db-backups/authentik/2026-02-25.sql.gz /tmp/
scp 192.168.88.19:/tmp/2026-02-25.sql.gz .
¶ Current PVC Assignments
| App | PVC Name | StorageClass | Size | Reason |
|---|---|---|---|---|
| Vault data (×3) | data-vault-{0,1,2} |
longhorn |
5Gi | Critical secrets storage |
| Vault audit (×3) | audit-vault-{0,1,2} |
longhorn |
5Gi | Audit log integrity |
| Authentik PostgreSQL | data-authentik-postgresql-0 |
longhorn |
8Gi | SSO DB, HA needed |
| Harbor DB | database-data-harbor-database-0 |
longhorn |
8Gi | Registry index DB |
| Harbor Redis | data-harbor-redis-0 |
longhorn |
2Gi | Cache, fast I/O |
| Nextcloud PostgreSQL | data-nextcloud-postgresql-0 |
longhorn |
5Gi | Migrated from NFS for reliability |
| VictoriaMetrics | server-volume-victoria-metrics-...-0 |
longhorn |
15Gi | Migrated post INC-001 |
| VictoriaLogs | server-volume-victoria-logs-...-0 |
longhorn |
15Gi | Migrated post INC-001 |
| Harbor Registry | harbor-registry |
nfs-subdir-retain |
30Gi | Image blobs now in MinIO S3 |
| Harbor JobService | harbor-jobservice |
nfs-subdir-retain |
2Gi | Job queue data |
| Harbor Trivy | data-harbor-trivy-0 |
nfs-subdir-retain |
5Gi | Vulnerability DB cache |
| Grafana | grafana |
nfs-subdir-retain |
5Gi | Dashboards, plugins |
| LifeOps PostgreSQL | postgres-storage-postgres-0 |
nfs-subdir-retain |
5Gi | App DB |
| GHA Runners | ephemeral work PVCs | nfs-subdir-delete |
10Gi | Auto-deleted after CI run |
| Nextcloud app data | nextcloud-nextcloud |
nfs-synology |
50Gi | User files, needs HDD capacity |
Note on VictoriaMetrics and VictoriaLogs: These were originally on
nfs-subdir-delete(50Gi each) but were migrated tolonghorn(15Gi each) after INC-001 — the TrueNAS NFS outage took down monitoring during the outage itself, making diagnosis harder.
¶ When to Use Which Storage
| Scenario | Recommended | Reasoning |
|---|---|---|
| PostgreSQL / databases | longhorn |
Consistent IOPS, 3-replica HA, no NFS latency spikes |
| Monitoring time-series data | longhorn |
Must stay up during NFS outages for diagnosis |
| Container registry blobs | nfs-subdir-retain (or MinIO S3) |
RWX needed, large objects, NVMe is fast enough |
| CI runner workspaces | nfs-subdir-delete |
Ephemeral, auto-cleaned, no retention needed |
| Large user files (Nextcloud) | nfs-synology |
21TB HDD pool, capacity >> performance |
| Shared config/plugins (Grafana) | nfs-subdir-retain |
RWX, small, fast enough on NVMe |
| Object storage (backup/traces) | MinIO | Not a K8s StorageClass — use S3 API directly |